Une question entre dans votre instance souveraine. Voici ce qui se passe réellement.
Une IA souveraine et privée, dédiée à votre organisation jamais mutualisée, jamais partagée.Mais une IA privée ne suffit pas. Un LLM avec RAG ne fait que 15 % du travail. Les 85 % restants déterminent si la réponse est fiable, sourcée et défendable devant un auditeur. Voici les 5 couches architecturales qui font la différence et qui tournent exclusivement sur vos données, dans votre instance.
Étape 1
Souveraineté et isolation
Votre instance. Votre modèle. Vos règles.
Chaque client dispose de sa propre instance isolée. Aucun partage d'information, aucune fuite de contexte entre locataires. Vos documents ne sont jamais utilisés pour entraîner un modèle tiers.
Frontier → distillation souveraine. Les connaissances des modèles frontier sont transférées vers des DSLM compacts (3–7B paramètres) hébergeables on-premise. Qualité frontier, hébergement souverain, coûts maîtrisés.
Architecture Zero-Knowledge. 3 modes de déploiement : SaaS partagé, Cloud privé / BYOC, On-Premise (compatible air-gap). Vous choisissez. Vous changez. Vos données restent là où vous le décidez.


Étape 2
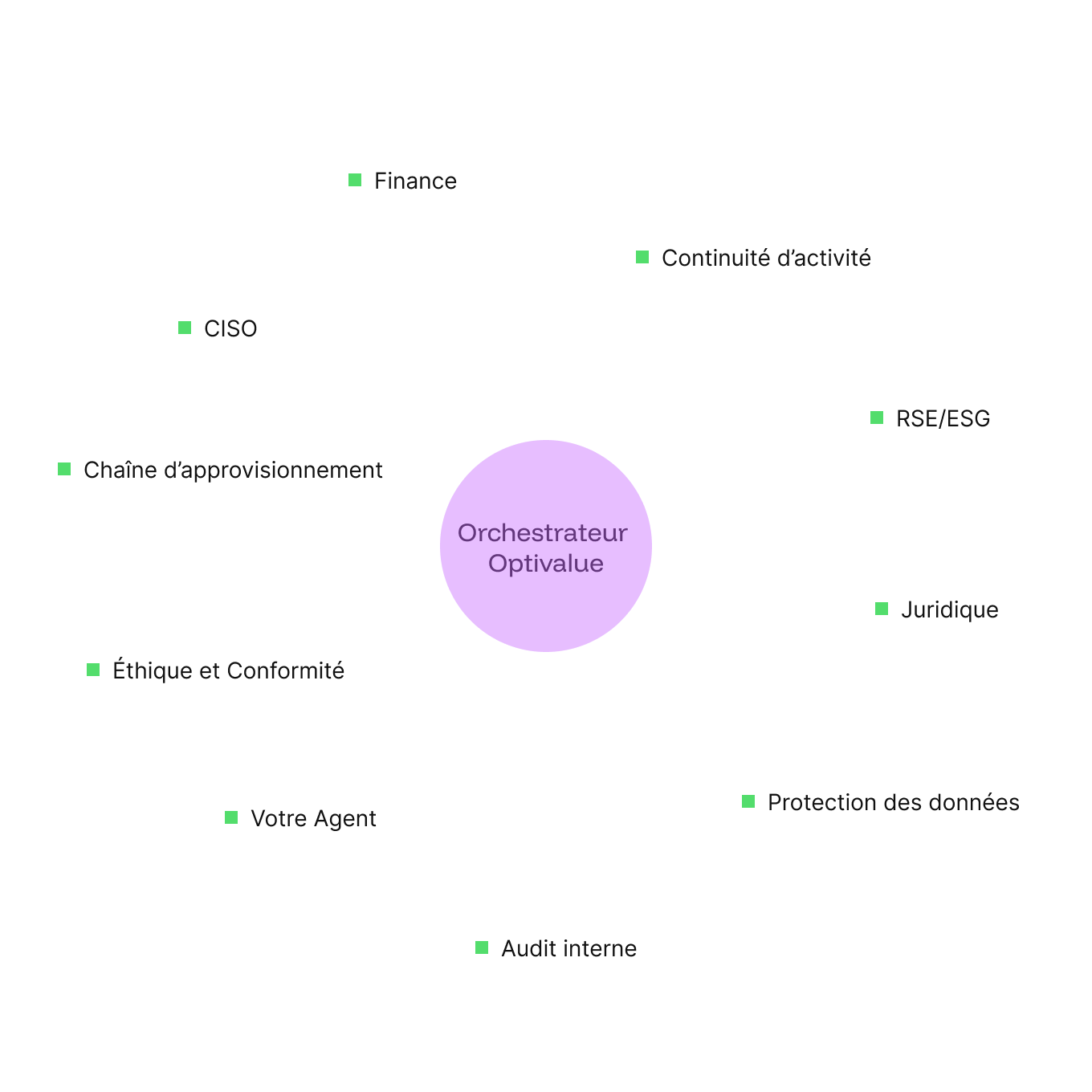
Orchestration multi-agents : l'IA prépare, l'humain décide
Orchestration multi-agents : l'IA prépare, l'humain décide 89 agents spécialisés. En équipe. Jamais un seul LLM.
Une architecture LLM + RAG classique interroge un unique modèle généraliste pour chaque question. Optivalue.ai déploie des DSLM (Domain-Specific Language Models) 89 agents spécialisés par domaine, formatés en Skills modulaires, avec leurs propres instructions, templates et règles.Le travail se fait en plusieurs niveaux, comme une organisation humaine :
Niveau 1 : la première équipe répond. L'Orchestrateur analyse le domaine de chaque question et lance en parallèle les agents pertinents (pattern Swarm). Un questionnaire multi-domaines active simultanément les agents Finance, RH, RGPD et IT chacun dans son contexte isolé, jusqu'à 100 sous-agents en parallèle.
Niveau 2 : une seconde équipe vérifie. Avant toute restitution, d'autres agents contrôlent : la source est-elle réelle ? le score est-il justifié ? la recommandation tient-elle la route ?
Niveau 3 :l'humain tranche. L'expert reçoit une proposition sourcée, scorée et argumentée, qu'il valide, corrige ou enrichit. Jamais une page blanche.
Quatre modes d'orchestration s'adaptent à chaque situation : vitesse, précision, coût ou autonomie complète.
Étape 3
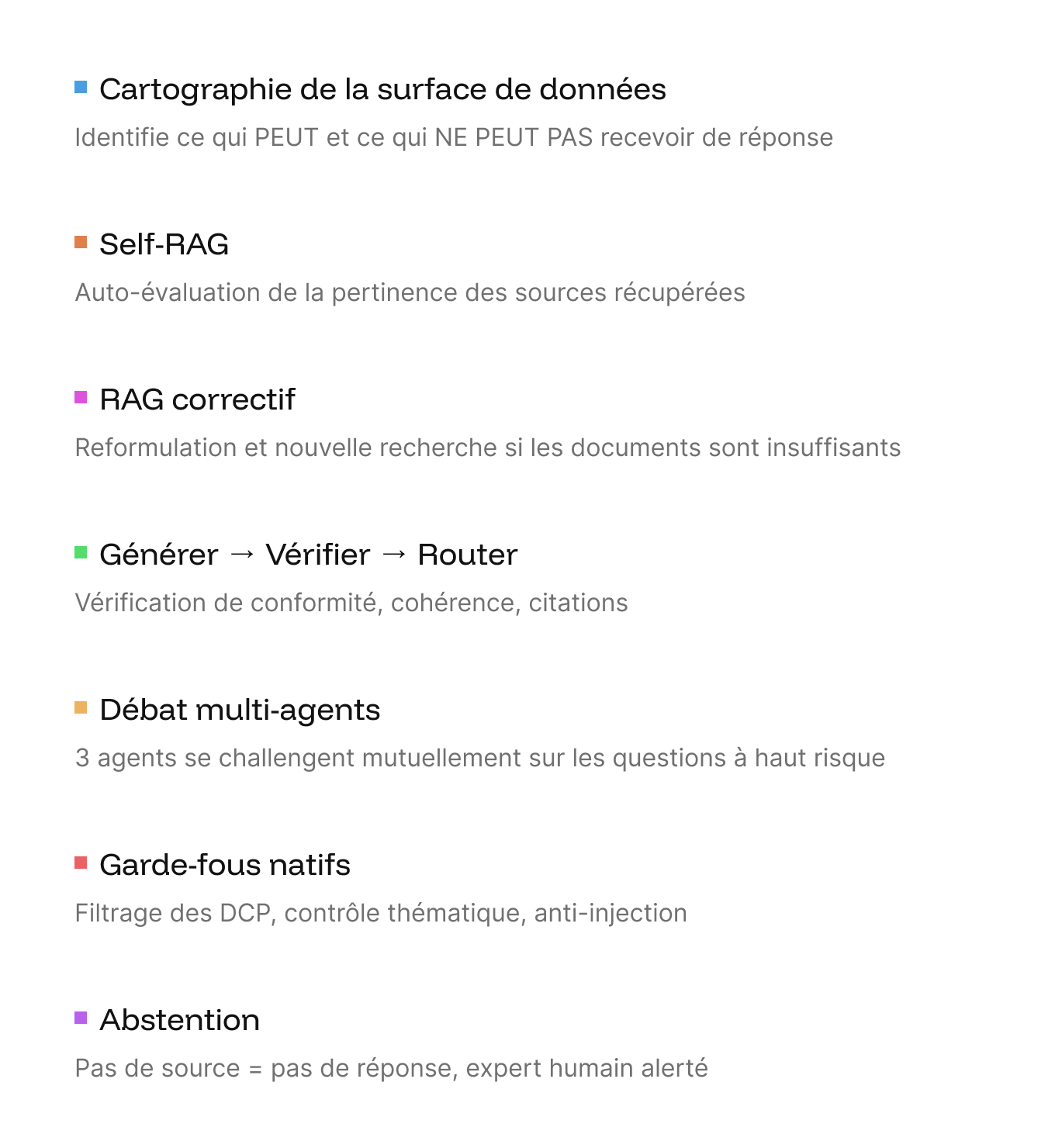
Anti-hallucination
7 couches de protection. Zéro hallucination.
C’est le différenciateur clé. Un LLM avec RAG récupère des documents et génère une réponse. Optivalue.ai fait passer chaque réponse à travers 7 couches de vérification indépendantes avant qu’elle n’atteigne l’utilisateur.
La ligne de défense ultime : l’abstention. Quand le système n’a pas de source, il ne répond pas. Il signale la lacune, identifie le bon expert et lui transfère la question. Le seul acteur du marché dont l’IA sait dire « Je ne sais pas ».
Pour les questions à haut risque, un débat dialectique oppose trois agents (Commercial, Critique, Juridique) avant de produire la réponse finale. Résultat : une réponse nuancée, qualifiée et défendable.

Étape 4
Agent Shredder
Avant de répondre, comprendre la véritable intention de la question.
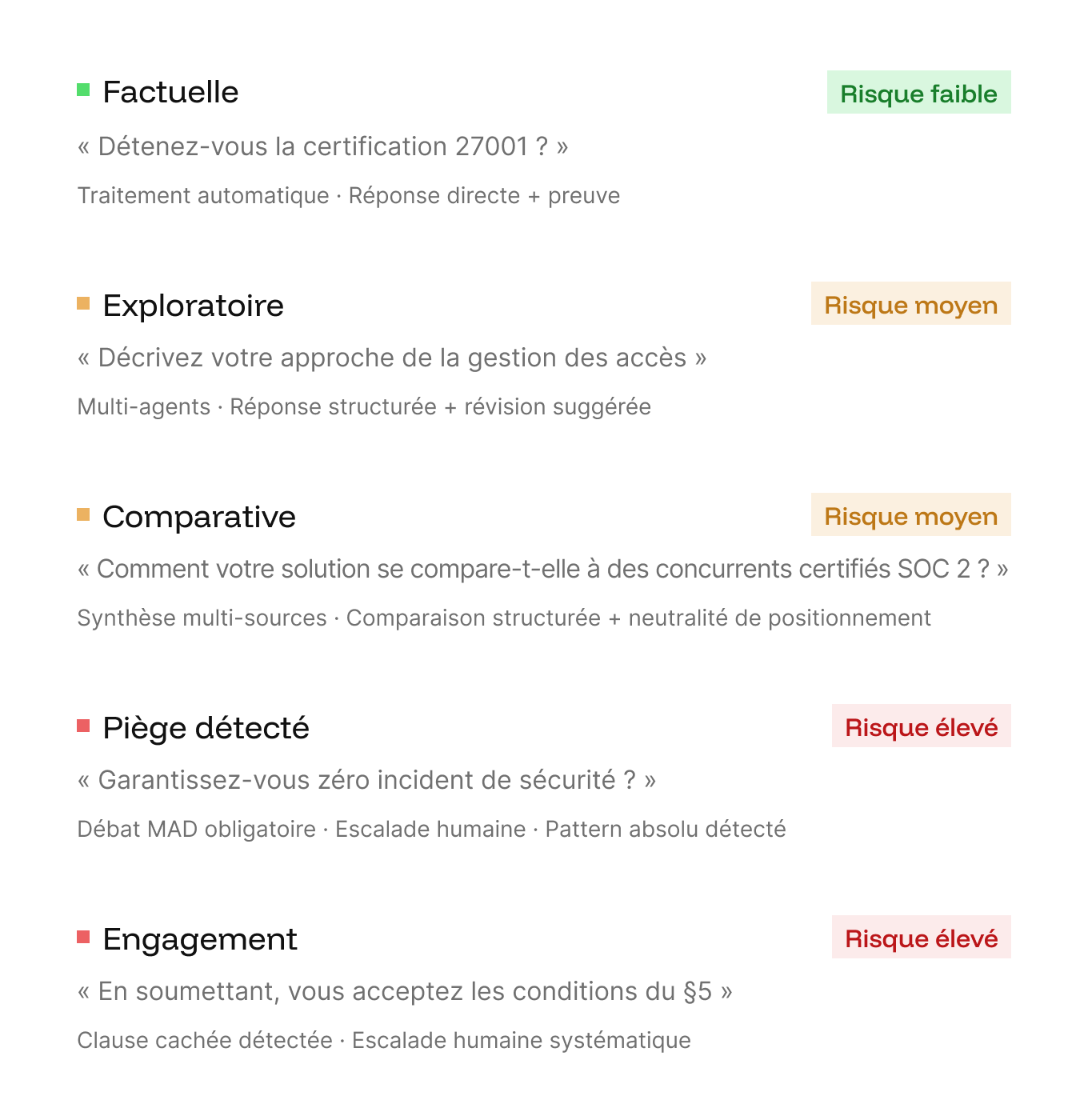
Un questionnaire de 200 questions contient 5 types radicalement différents : factuelles, exploratoires, comparatives, pièges et engagements contractuels. Un LLM avec RAG les traite toutes de la même manière.
L’Agent Shredder analyse chaque question avant toute génération. Il classifie l’intention, détecte les questions pièges (absolus, doubles négations, engagements implicites) et attribue un niveau de risque qui détermine l’ensemble du workflow en aval.
Une question comme « Garantissez-vous un uptime de 100 % ? » ne déclenche pas le même pipeline que « Détenez-vous la certification ISO 27001 ? »
Étape 5
Score de confiance explicable
Chaque réponse notée, expliquée et prouvée. Chaque questionnaire rend le suivant plus fiable. Conforme à l'EU AI Act.
Sur chacun de vos cas d'usage TPRM, RGPD, ISO 27001, RFP, due diligence, chaque réponse produite affiche un score de confiance, une source et quand c’est nécessaire une recommandation.
C’est un score qui fait progresser vos réponses. Chaque réponse est l’occasion d’apprendre et d’enrichir votre base de connaissance.
La prochaine réponse sur le même cas d'usage ou un cas voisin, devient alors plus précise, plus rapide et plus haute en confiance.
Votre capital de réponses se capitalise : questionnaire après questionnaire, vos réponses s'améliorent.

