A question enters your private AI. Here's what really happens.
A sovereign, private AI dedicated to your organization never shared, never pooled.But a private AI isn't enough. An LLM with RAG only does 15% of the work. The remaining 85% determines whether the answer is reliable, sourced and defensible in front of an auditor. Here are the 5 architectural layers that make the difference all running exclusively on your data, within your own instance.
Step 1
Sovereignty & Isolation
Your instance. Your model. Your rules.
Each customer has their own isolated instance. No information sharing, no context leakage between tenants. Your documents are never used to train third-party models.
Frontier → sovereign distillation. Knowledge from frontier models is transferred to compact DSLMs (3—7B parameters) that can be hosted on-premise. Frontier quality, sovereign hosting, controlled costs.
Zero-Knowledge architecture. 3 deployment modes : Shared SaaS, Private Cloud/BYOC, On-Premise (air-gap compatible). You choose. You are changing. Your data stays where you want it to be.


Step 2
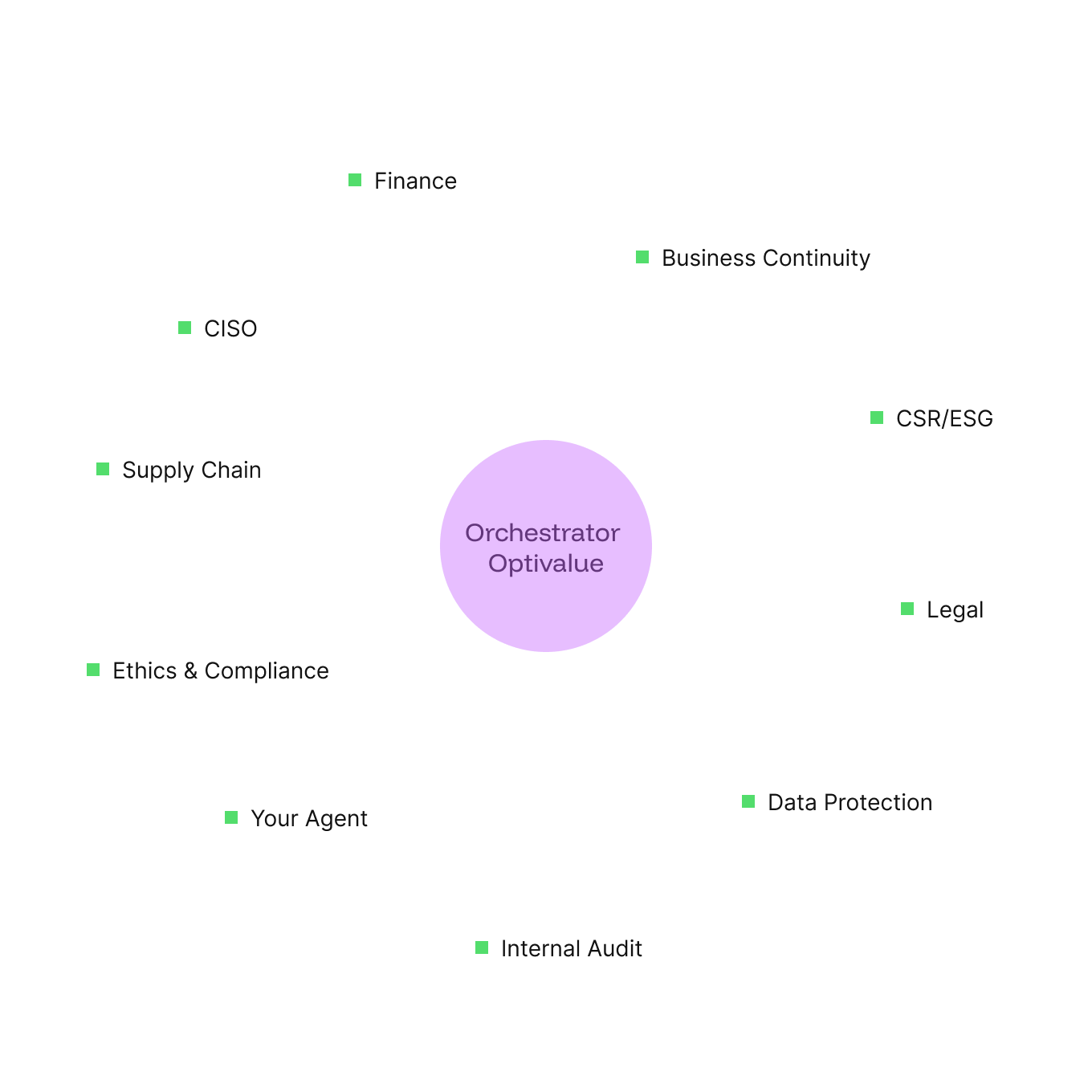
Multi-agent orchestration: AI prepares, humans decide.
Multi-agent orchestration: AI prepares, humans decide. 89 specialized agents. Working as a team. Never a single LLM.
A standard LLM + RAG architecture queries a single generalist model for every question. Optivalue.ai deploys DSLMs (Domain-Specific Language Models) 89 agents specialized by domain, structured as modular Skills, each with their own instructions, templates and rules.
The work unfolds across multiple layers, much like a human organization:
Layer 1 : the first team answers. The Orchestrator analyzes the domain of each question and simultaneously launches the relevant agents (Swarm pattern). A multi-domain questionnaire activates Finance, HR, GDPR and IT agents in parallel each in its own isolated context, up to 100 sub-agents running simultaneously.
Layer 2 : a second team reviews. Before any output is returned, a separate set of agents audits the work: Is the source real? Is the score justified? Does the recommendation hold up?
Layer 3 : the human decides. The expert receives a sourced, scored and argued proposal to validate, correct or enrich. Never a blank page.
Four orchestration modes adapt to every situation: speed, precision, cost or full autonomy.
Step 3
Anti-hallucination
7 layers of protection Zero hallucinations.
It is the key differentiator. An LLM with RAG retrieves documents and generates a response. Optivalue.ai gets every response through 7 independent verification layers before it reaches the user.
The ultimate line of defense:forbearance. When the system has no source, it doesn't respond. He points out the gap, identifies the right expert, and transfers the question to him. The only player in the market whose AI can say “I don't know.”
For high-risk questions, a Dialectical debate pit three agents (Commercial, Critical, Legal) against each other before producing the final answer. The result: a nuanced, qualified and defensible response.


Step 4
Shredder Agent
Before answering, understand the true intent of the question.
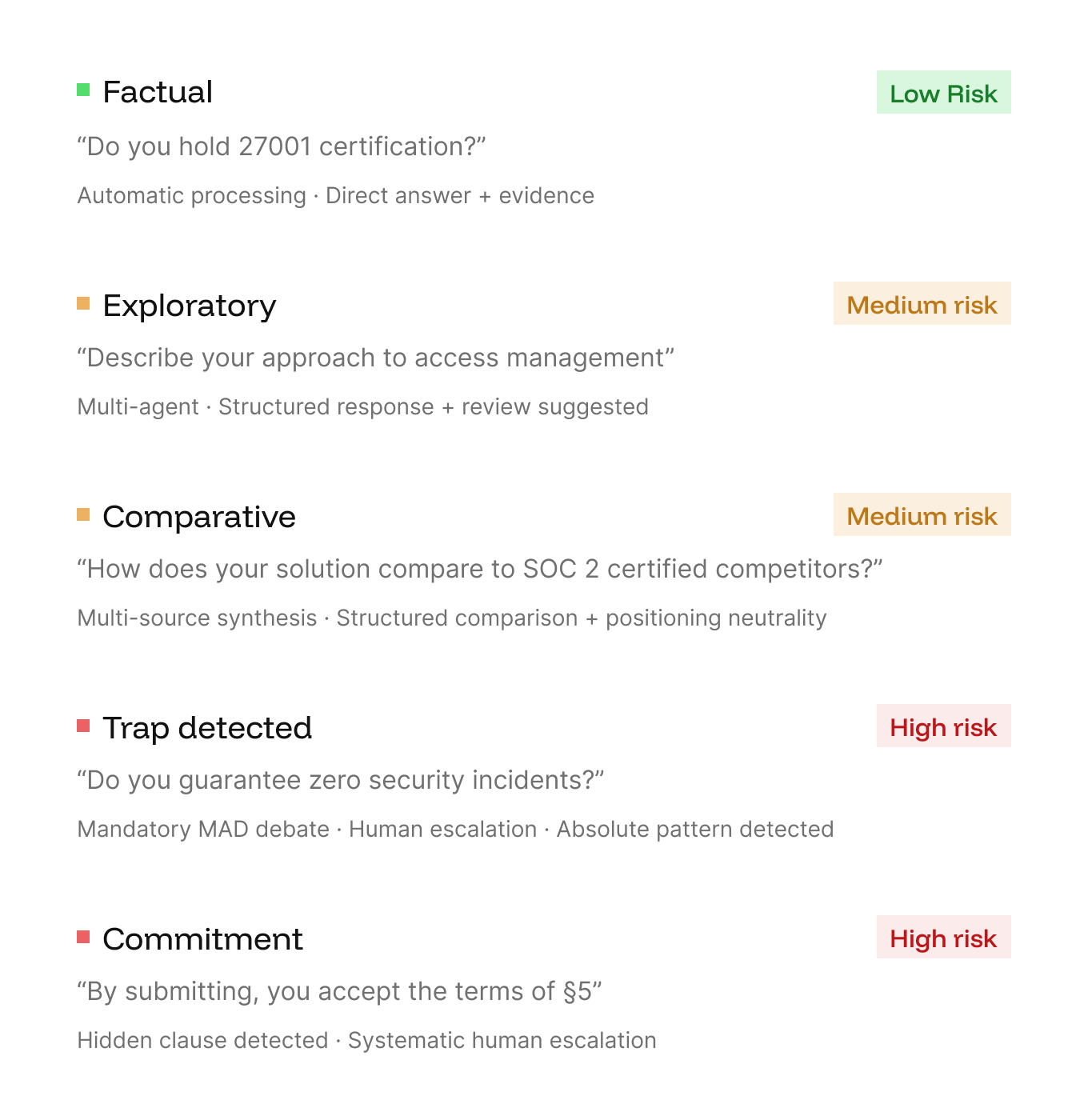
A questionnaire of 200 questions contains 5 radically different types: factual, exploratory, comparative, pitfalls and contractual commitments. An LLM with RAG treats them all the same.
The Shredder Agent analyze each question before any generation. It classifies intent, detects trick questions (absolutes, double negations, implicit commitments), and assigns a risk level that determines the entire downstream workflow.
A question like “Do you guarantee a 100% uptime? does not trigger the same pipeline as “Do you have ISO 27001 certification?” ”
Step 5
Explainable trust score
Every answer scored, explained and proven. Every questionnaire makes the next one more reliable. EU AI Act compliant.
Across all your use cases TPRM, GDPR, ISO 27001, RFP, due diligence, every generated answer displays a confidence score, a source, and where relevant, a recommendation.
A score that improves your answers over time. Every answer is an opportunity to learn and enrich your knowledge base. The next response on the same or a related use case becomes more precise, faster, and more confident.
Your answer capital compounds: questionnaire after questionnaire, your responses keep getting better.

